Parlare di protezione dei testi digitali sembra oggi una grande sfida. Una sfida che si combatte su di un campo minato a suon di tonanti pareri contrastanti.
Ogni Paese ha infatti le proprie regolamentazioni (che troppo spesso ricalcano ancora i vecchi modelli riguardanti l’editoria cartacea) e creare un “decalogo globale” è pressoché impossibile, data l’assenza di un riferimento giuridico univoco. Se a tutto questo aggiungiamo poi il fatto che la circolazione di un qualsivoglia testo diventa difficilmente mappabile una volta entrato nei lunghi (e a volte “oscuri”) canali della Rete, il tutto si complica.
Come accennato, in molti Paesi la distinzione tra prodotti cartacei e digitali pare non essere stata ancora afferrata. Si continua quindi a trattare i due campi alla stessa stregua.
In Italia, per esempio, esiste il concetto di diritto d’autore, che è disciplinato da una leggededicata, la n. 633 del 1941. Un po’ vecchiotta, direte voi, soprattutto se si pensa che – a parte qualche rarissima modifica – il suo impianto è rimasto sostanzialmente identico negli anni.
I settori maggiormente modificati dal passare del tempo sono quelli relativi, per esempio, alla pirateria digitale (di opere letterarie in senso stretto, come anche di opere musicali o cinematografiche) – il cosiddetto free riding, che si verifica ogni qualvolta si accede a un contenuto informativo eludendo il pagamento previsto per utilizzarlo – , alla tutela delle banche dati, alla creazione e protezione del copyright digitale, alla protezione del chip, e via discorrendo.
Il cugino di matrice anglo-americana (legata cioè ai cosiddetti sistemi di common law) dell’italianissimo diritto d’autore è il famoso copyright, la cui principale differenza risiede nel tutelare maggiormente i diritti patrimoniali derivanti dallo sfruttamento dell’opera dell’ingegno, piuttosto che i diritti morali dell’autore.
L’entrata in scena del nuovo universo digitale ha sensibilmente impattato su questo ambito legislativo, che vede sorgere ulteriori complicanze.
Un’informazione priva di materialità è per sua natura più vulnerabile, quindi necessita di una maggiore protezione. Tutto ciò, però, non deve frenare la possibilità di far circolare in forma gratuita, dietro benestare dell’autore o degli autori, l’informazione e la conoscenza.
La struttura classica del diritto d’autore, come anche quella del copyright, risulta ad oggi eccessivamente rigida, se riferita al campo digitale. Ciò ha portato allo studio di alcune possibili alternative.

Il primo tentativo in tal direzione è stata la creazione della GNU General Public License (GNU GPL), una forma di licenza sviluppata da Richard Stallman nel 1984 con l’obiettivo di sedare le lotte tra software a pagamento, i cosiddetti programmi open source e i sostenitori del software libero. Nasce così il concetto di copyleft, la cui terminologia, applicata in un secondo momento, prende origine da un divertente gioco di parole basato sul fatto che il termine right di copyright indica in inglese sia la direzione “destra”, sia il termine “diritto” in senso legale. Tale natura opposta è servita da spunto per rappresentare graficamente il simbolo del copyleft che restituisce un’immagine, per così dire, “specchiata” del simbolo del copyright.
Il copyleft è in pratica un sistema di licenze che dà il pieno controllo dell’opera all’autore, il quale ne stabilisce modi di utilizzo, diffusione e a volte anche modifica da parte dei fruitori, pur nel rispetto di alcune condizioni basiche.
In Italia l’applicazione di tale concetto è ancora una chimera. L’esistenza della SIAE, quale organo superiore di gestione dei diritti di utilizzazione, è un ostacolo insormontabile per qualsiasi agile atleta di salto in alto: l’”affiliazione” a tale ente non permette all’autore di promuovere e diffondere la propria opera tramite canali altri.
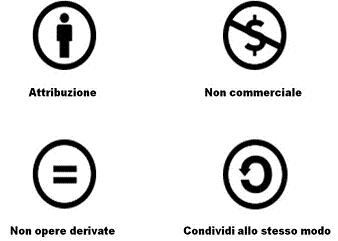
Rappresentazione grafica delle quattro varianti del progetto Creative Commons. (Fonte: http://www.creativecommons.it/Licenze)
Una serie di licenze create, invece, per ambiti non strettamente informatici è quella delleCreative Commons. Il progetto sembra realmente interessante: a una licenza “base”, formulata da un team di giuristi legati al progetto, si accostano quattro varianti combinabili tra loro, allo scopo di “ammorbidire” la rigida struttura del copyright. In che modo? In pratica, attraverso questo set di licenze, l’autore – o chi detiene i diritti di copyright – può trasmettere alcuni di questidiritti al pubblico e conservarne altri.
La formulazione dell’intera struttura fa sempre riferimento – nella fase iniziale – al sistema giuridico statunitense in cui è nata, per poi appoggiarsi all’ordinamento locale (nel nostro caso la base è sempre la legge del ’41 sul diritto d’autore). In Italia il progetto approda nel 2003 ed è seguito da due grandi istituzioni: il Dipartimento di Studi giuridici dell’Università di Torino per quanto riguarda gli aspetti legali e l’IEIIT-CNR di Torino per quanto riguarda gli aspetti tecnico-informatici.
Allo scopo di facilitare la comprensione delle quattro clausole, sono state create delle visuals, cioè delle icone, che le rappresentano graficamente.

Rappresentazione grafica delle parti di una licenza Creative Commons (Fonte: http://creativecommons.org/worldwide)
Altra particolarità che secondo i più ha contribuito al successo delle Commons è la struttura, per così dire, di presentazione, composta di tre parti: ilLegal Code, che costituisce la licenza effettiva che rileva a livello giuridico; il Commons Deed, una versione sintetica della licenza, priva di termini astrusamente giuridici, fatta apposta per tutti quelli che non si cibano quotidianamente di “giuridichese”; e il Digital Code, costituito da una serie di metadati necessari alla localizzazione della licenza da parte dei vari motori di ricerca.
Altra soluzione, e qui andiamo a toccare corde molto delicate, è quella dell’applicazione del DRM, al secolo Digital Rights Management. Il suo utilizzo, come ormai noto, ha fatto infuriare orde di lettori digitali che, accolta di buon grado la tecnologia, si sono visti sbarrare la strada verso la lettura.
Si tratta di sistemi tecnologici che si pongono come obiettivo primario quello diproteggere i titolari del diritto d’autore, e i diritti ad esso connessi, affidandone la gestione direttamente ai suddetti titolari. Tutto ciò ovviamente avviene inibendo la copiae/o la stampa non autorizzata dell’opera e limitando il numero di device su cui un ebook può essere letto.
Alcuni di questi software vengono rilasciati direttamente da aziende che producono anche dispositivi di lettura (è il caso di Amazon, per esempio), altri invece vengono semplicemente gestiti da aziende terze, come nel caso di Adobe, leader incontrastato con il suo Adobe Digital Editions.
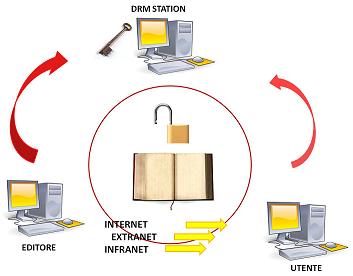
Rappresentazione grafica del meccanismo di funzionamento di DRM Adobe
Nato con l’obiettivo principale di combattere la pirateria, il concetto “chiuso” di DRM riesce a scontentare, però, anche chi i contenuti li acquista in maniera lecita; questo per via della suaestrema rigidità che, lungi dall’essere riuscita a contrastare in maniera radicale il fenomeno del free riding tanto paventato, si teme possa addirittura spingere alla pirateria digitale i lettori più corretti.
Soluzioni più “soft” semplificherebbero, forse, il processo di lettura digitale e la renderebbero più appetibile, soprattutto agli occhi degli scettici tradizionalisti (tra le cui fila, a volte, m’intrufolo!). È il caso di sistemi quali il social DRM o watermark, che anziché inibire la copia di un contenuto, integra al suo interno una serie di dati relativi all’acquirente per rendere il file univocamente riconducibile a chi lo ha acquistato, scoraggiandone in tal modo la sua duplicazione e diffusione irregolare e rendendo possibile la fruizione del contenuto su diversi device.
E voi, cari lettori digitali, che cosa ne pensate? Credete che le soluzioni studiate fino ad ora per tutelare autore, opere e diffusione del sapere siano accettabili o no? E nella vostra pratica di lettura quali preferite?
Nessun commento:
Posta un commento